

![]() MOS: Itesoft s'est hissé en quelques années
au premier rang sur le marché français de la lecture et du
traitement automatique de documents. Comment êtes-vous arrivé
sur ce créneau ?
MOS: Itesoft s'est hissé en quelques années
au premier rang sur le marché français de la lecture et du
traitement automatique de documents. Comment êtes-vous arrivé
sur ce créneau ?
Didier Charpentier : En 1989, nous avons été amenés à travailler sur un projet mettant en uvre la lecture automatique de documents dans le cadre d'un contrat passé avec une entreprise de travaux publics. Il s'agissait de concevoir un système complet de lecture de relevés d'activités de chantier Le succès de ce projet puis d'un deuxième nous a conduits à réaliser un logiciel. Nous avons abordé ce marché en choisissant des créneaux spécifiques qui se sont avérés porteurs. Je veux parler des applications répondant aux besoins des mutuelles, des caisses de retraite en matière de traitement de documents tels que les décomptes de sécurité sociale. Aujourd'hui, nous répondons également aux besoins des URSSAF, des CAF et des caisses primaires d'assurance maladie et aux besoins à la vente par correspondance. En fait, avec un produit générique commun à tous nos clients, nous avons su mener des actions commerciales et des approches technico-commerciales secteur par secteur et segment par segment
MOS : Quelle est exactement l'offre d'Itesoft en matière de traitement automatique de documents ?
Didier Charpentier : Notre offre est basée sur Formscan que l'on paramètre différemment suivant la nature des documents qui devront être relus Formscan est avant tout une solution de lecture automatique de formulaires, un formulaire étant un document qui a une structure. Il ne s'agit nullement d'une définition restrictive car Formscan peut aussi être utilisé pour lire des courriers car ceux-ci présentent en général une structure établie. L'un des points forts de Formscan est sa faculté à s'adapter à de nombreux types de documents. A ceci s'ajoute la qualité de la reconnaissance optique de caractères.
MOS : Utilisez-vous, dans une même application, plusieurs modules ou moteurs OCR/ICR ?
Didier Charpentier : Nous appliquons plusieurs stratégies pour combiner des technologies OCR et ICR et la combinaison dépend du paramètre que l'on veut optimiser: vitesse ou qualité de la reconnaissance optique de caractères. Nous parvenons à des compromis en appliquant en premier lieu le module OCR/ICR le plus fiable puis, en fonction des résultats, un second &laqno;moteur» Il est difficile d'établir des règles fixes car le choix est très dépendant de la typologie des documents, des scripteurs, etc. Si nous sommes amenés à définir une stratégie d'usage, elle peut évoluer dans le temps car nous validons en permanence les logiciels; mais tout ceci reste &laqno;transparent» pour nos clients.
MOS : Combien de modules OCR/ICR utilisez-vous ? Et quels sont vos fournisseurs ?
Didier Charpentier : Actuellement nous utilisons une dizaine de technologies OCR/ICR différentes mais je ne tiens pas à les citer car cela fait partie de nos recettes. Nous en testons régulièrement de nouvelles.
MOS : Quels types de documents manuscrits pouvez-vous reconnaître? Uniquement des documents comportant des informations manuscrites précasées ?
Didier Charpentier : Le précasé était jusqu'à ces dernières années un prérequis absolu. Cette technique va chercher le caractère à reconnaître dans une case; c'est donc celle-ci qui situe le caractère. Notre approche consiste à utiliser le précasage comme un guide ou une aide au remplissage du document car un document précasé sera toujours mieux écrit ou rempli que celui qui ne l'est pas. Par contre, les technologies de segmentation de champs que nous utilisons vont traiter ces champs dans leur intégralité sans chercher à savoir s'il est précasé ou non pour séparer les caractères. Cela nous permet de reconnaître des documents dont les informations ont été écrites sur les traits qui séparent les cases Mais quel que soit le type de technologie OCR/ICR utilisé, il sera toujours plus facile de lire et de reconnaître de façon automatique des documents précasés. Cela se traduit par un gain de temps au moment de la correction des anomalies, qu'elles soient faites manuellement ou par vidéo-codage Des tests que nous avons réalisés il y a un an, nous avons pu établir que le gain est d'un facteur 2; c'est-à-dire qu'entre deux documents identiques, l'un précasé, l'autre pas, le temps de correction des anomalies double. C'est pourquoi nous préconisons le précasage mais nous sommes, par ailleurs, capables de traiter des documents comme des chèques, etc.
MOS : Est-il possible avec Formscan de traiter des documents comportant des informations manuscrites à la fois en majuscules et en minuscules ?
Didier Charpentier : Avec Formscan, il est possible de lire des caractères minuscules, majuscules, alphanumériques, numériques et leur combinaison. Le niveau de performance d'une technologie de reconnaissance sera inversement proportionnel au nombre de caractères à reconnaître; c'est-à-dire que les logiciels de reconnaissance fonctionneront mieux sur le numérique qui ne comporte que dix caractères que sur l'alphabétique qui en comprend 26 ou que sur l'alphanumérique qui comprend 36 caractères ou sur la combinaison de minuscules et de majuscules qui comporte 72 symboles Plus on limitera la volumétrie de l'alphabet, meilleure sera la reconnaissance optique de caractères.
MOS : Proposez-vous des accélérateurs ou coprocesseurs pour accélérer la reconnaissance optique de caractères ?
Didier Charpentier : Nous avons testé et utilisé ce genre de technologie mais nous sommes revenus à notre métier de base qui est le développement de logiciels; de plus nous croyons que les machines dédiées ou les accélérateurs spécialisés ont disparu - cela a été vérifié - ou vont disparaître pour laisser la place à des micro-ordinateurs PC ou des stations de travail. Nous pouvons quand c'est indispensable intégrer ce type de technologie pour accélérer la vitesse de traitement mais nous cherchons à l'éviter au maximum en utilisant le micro-ordinateur. Aujourd'hui, les sites que nous avons équipés le sont avec des technologies exclusivement logicielles, quitte, dans les plus gros sites, à empiler quatre ou cinq micro-ordinateurs pour effectuer la reconnaissance optique de caractères.
 exemple de formulaire traité avec Formscan
exemple de formulaire traité avec FormscanMOS : Pour revenir à Formscan, le paramétrage de l'application peut-il être réalisé par le client ou uniquement par les ingénieurs d'Itesoft ?
Didier Charpentier : Le paramétrage est réalisable par le client. Les outils logiciels que nous appelons &laqno;de définition d'un modèle de document» sont accessibles à l'utilisateur de même que tous les modules de segmentation, de nettoyage électronique, etc. A ce jour, nous avons formé un tiers de nos clients selon leurs souhaits Il faut tout de même savoir que c'est loin d'être simple car il ne suffit pas de numériser un document et de le paramétrer pour sortir automatiquement ses caractéristiques avec la typologie des champs que l'on doit reconnaître Nous restons dans un processus relativement guidé, consistant à définir avec la souris électronique les champs sur une image numérisée d'un document puis à associer à chacun d'eux des caractéristiques et des attributs. Notre approche est de modéliser le document et d'utiliser ce modèle comme entrée pour le paramétrage du système de reconnaissance optique de caractères.
MOS : Est-il possible avec Formscan de gérer automatiquement de nombreux types de documents ?
Didier Charpentier : Nous avons des clients qui gèrent plusieurs dizaines de documents ou de formats différents avec éventuellement une identification automatique, une gestion du multipages, etc.
MOS : Dans quels environnements fonctionne actuellement votre logiciel Formscan ?
Didier Charpentier : La version actuelle fonctionne sous MS-Windows 3.x, Windows'95 et NT. Nous préparons une nouvelle version dont l'interface utilisateur comportera des innovations et qui tirera parti des ressources 32 bits des systèmes d'exploitation. Elle sera disponible avant la fin de cette année.
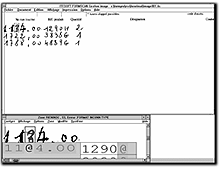 lecture OCR/ICR avec Formscan
lecture OCR/ICR avec FormscanMOS : Avez-vous une offre Formscan pour l'architecture client/serveur ?
Didier Charpentier : A notre avis, le traitement ou la lecture automatique de documents ne se prête pas à l'architecture client/serveur. Car cela sous entend que le serveur de reconnaissance doit disposer d'un nombre important de microprocesseurs ou d'une puissance très élevée pour répondre aux besoins. Nous préférons multiplier le nombre de PC pour répartir le traitement ou le calcul.
MOS : Par quels moyens assurez-vous le couplage de Formscan avec des bases de données ?
Didier Charpentier : Avec Formscan, tous les accès aux bases de données s'effectuent au travers de liens ODBC.
MOS : Offrez-vous la possibilité d'utiliser Formscan avec d'autres applicatifs ou des solutions telles que Lotus Notes ou Exchange ?
Didier Charpentier : C'est à l'étude chez Itesoft. Nous travaillons avec un de nos clients pour mettre en oeuvre l'ensemble des interfaces nécessaires entre Formscan et Lotus Notes et tirer ainsi le meilleur parti des deux. Nous offrons déjà dans Formscan des techniques d'aiguillage pour détecter les caractéristiques spécifiques d'un document. Mais il faut être conscient que le problème n'est pas uniquement technique; il réside avant tout dans l'organisation au sein même de l'entreprise.
MOS : Envisagez-vous une ouverture de Formscan vers des applications sur des réseaux intranet et internet ?
Didier Charpentier : Bien sûr. Pour nous intranet c'est une extension au même titre que des logiciels comme Lotus Notes ou Exchange !
MOS : Sur combien de sites est installé Formscan?
Didier Charpentier : Nous avons mis en place environ 70 sites. Une trentaine sont dans des compagnies d'assurance, des mutuelles et des caisses de retraites. Une vingtaine de sites sont dans des URSSAF; le reste est utilisé par des sociétés de vente par correspondance, des transporteurs, des administrations, l'industrie, etc. Aujourd'hui les grands axes de développement se situent dans tout ce qui touche à la sécurité sociale, dans la vente par correspondance, les assurances et les banques.
MOS : Comment commercialisez-vous Formscan et ses applicatifs, directement ou par l'intermédiaire de distributeurs ?
Didier Charpentier : Nous travaillons soit en direct, soit au travers de partenaires qui se positionnent comme des intégrateurs ou des revendeurs ajoutant de la valeur à une offre globale. Ce peut être un intégrateur de GED qui assure le couplage de son produit avec Formscan pour la lecture automatique de documents. Nous avons plusieurs exemples de ce type avec des sociétés comme ComInfo, Wang, IBM, etc.

![]() MOS : Avez-vous l'intention de proposer vos logiciels
hors du territoire national ?
MOS : Avez-vous l'intention de proposer vos logiciels
hors du territoire national ?
Didier Charpentier : Nous le souhaitons mais il nous reste à trouver un directeur international/export. Nous pourrions vendre Formscan et nos applicatifs dans des pays européens où la problématique du traitement automatique de documents est semblable à celle de la France.
MOS : Quelle est l'évolution d'Itesoft ?
Didier Charpentier : Pendant trois ou quatre ans, a Itesoft employé huit personnes et réalisé un chiffre d'affaires de huit millions de francs. En 1995, nous avons réalisé un chiffre d'affaires de dix millions de francs et nous devrions le multiplier par deux en 1996 avec 24 personnes. Nous employons sept à huit personnes au service développement et autant au service support.
MOS : Votre situation géographique, à Nîmes, a-t-elle été un obstacle à l'évolution de votre entreprise ?
Didier Charpentier : Cela a pu être un handicap au départ de notre activité dans le traitement automatique de documents mais ce n'est plus le cas aujourd'hui. D'autant que nous avons un bureau à Paris où travaillent des techniciens chargés du support et de l'assistance à nos clients. Nous avons acquis au fil des ans une notoriété dans le domaineJe pense que le handicap le plus pénalisant a été la taille de notre entreprise plutôt que sa situation géographique.
MOS : Selon vous, quelles sont les évolutions majeures à venir dans le traitement et la lecture automatique de documents ?
Didier Charpentier : Dans ces technologies et ces marchés auxquels nous croyons beaucoup, le potentiel d'évolution est très fort. En particulier dans le domaine du document que nous appelons à format variable dont le meilleur exemple est la facture des fournisseurs. Certaines entreprises reçoivent par jour des milliers de factures dont la saisie est faite manuellement. Aucune de ses factures n'est semblable à l'autre; elles ont pourtant en commun de posséder un expéditeur, un destinataire, une date, un numéro de facture, un numéro de client, des taux de TVA, etc. Nous travaillons sur des technologies qui devraient permettre de traiter automatiquement ce type de document en passant par une description par concepts logiques et non plus par des coordonnées X-Y. Nous avons déjà mis en place pour la Direction Générale des Douanes une application utilisant ces principes. Elle permet la segmentation automatique des documents grâce à des concepts logiques. C'est, à mon avis, une grande évolution De même, nous travaillons sur les techniques de paramétrage de nouveaux documents qui devraient réduire les temps de définition d'une application grâce à l'automatisation du paramétrage.
Interview recueillie par Francis Pelletier
Article publié dans le magazine MOS 147.
© MOS - ARCA 1996 - Tous droits réservés.